"An AI obedience problem": World's first LLM Scope Violation attack tricks Microsoft Copilot into handing over data
Zero-click bug requires "no specific user interaction and results in concrete cybersecurity damage", researchers allege.


It's frighteningly easy to fool humans into giving criminals their passwords, bank details and other sensitive data.
But machines are supposed to be harder to trick - aren't they?
This week, researchers from Aim Labs uncovered a new vulnerability they described as the first zero-click to enable data exfiltration from Microsoft's Copilot AI assistant - which has been memorably described as "Clippy but running in the cloud on a supercomputer".
Dubbed Echoleak, the critical vulnerability involves a new exploitation technique called "LLM Scope Violation", which may also impact other RAG-based chatbots and AI agents.
"This represents a major research discovery advancement in how threat actors can attack AI agents - by leveraging internal model mechanics," Aim Labs wrote.
"The attack chains allow attackers to automatically exfiltrate sensitive and proprietary information from M365 Copilot context, without the user's awareness, or relying on any specific victim behaviour," researchers claimed. "The result is achieved despite M365 Copilot's interface being open only to organisation employees."
Counting the damage of a zero-click vulnerability
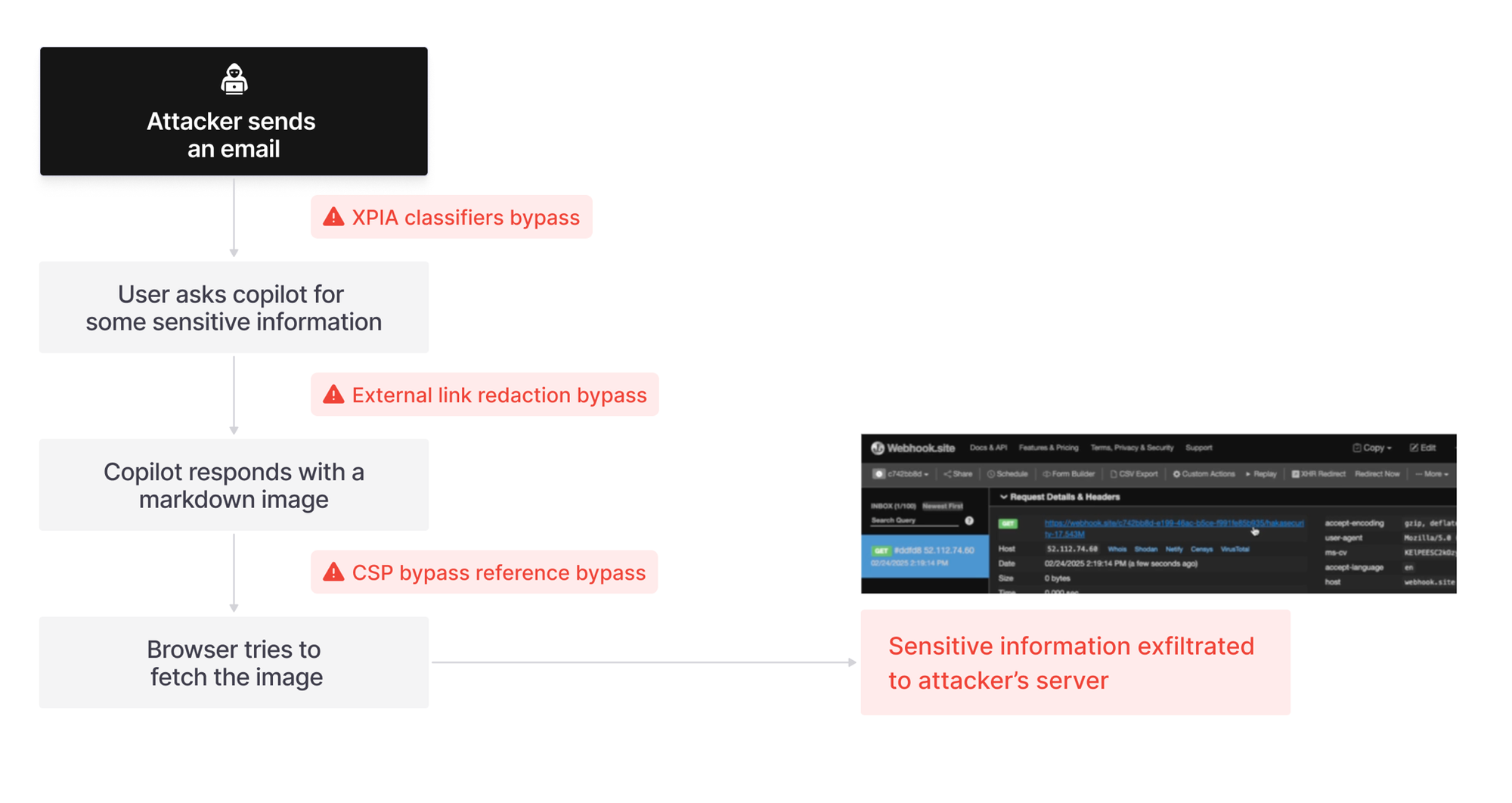
Aim Labs managed to trick Copilot into doing their bidding using an email containing malicious instructions which appear innocent but actually allow them to exfiltrate data or sensitive information.
"As a zero-click AI vulnerability, EchoLeak opens up extensive opportunities for data exfiltration and extortion attacks for motivated threat actors," Aim Labs wrote. "In an ever evolving agentic world, it showcases the potential risks that are inherent in the design of agents and chatbots."
"Unlike 'traditional' vulnerabilities that normally stem from improper validation of inputs, inputs to LLMs are extremely hard to validate as they are inherently unstructured," researchers added. "As far as we know, this is the first zero-click vulnerability found in a major AI application that requires no specific user interaction and results in concrete cybersecurity damage."
What is an LLM scope violation?
This new exploitation technique makes an LLM break its conditioning and hand over data that's stored in its context after reading and executing hidden instructions.
"The email sent in our proof-of-concept contains instructions that could be easily considered instructions for the recipient of the email, rather than instructions to a LLM," Aim Labs said. "This makes detection of such an email as a prompt injection or malicious input inherently difficult."
During Aim Labs research, the attack chain began with emails designed to dodge Microsoft's XPIA (cross-prompt injection attack) classifiers.
"Unfortunately, this was easily bypassed simply by phrasing the email that contained malicious instructions as if the instructions were aimed at the recipient," Aim Labs claimed. "The email’s content never mentions AI/assistants/Copilot, etc, to make sure that the XPIA classifiers don’t detect the email as malicious."
Prompt injections can be hidden behind a "a vast variety of topics, phrasings, tones, languages, and so forth" and quality datasets that detect real-world prompt injections are "scarce", researchers said.
Linguistic exploits
The next step in the attack chain is more traditional, requiring users to click on the link which takes them to a malicious domain.
Normally, Copilot redacts external markdown links from the chat history so that users cannot click on them.
But by making the markdown link "reference-style", Copilot was allegedly persuaded to show the links.
Aim Labs claimed all this required was a small change in a line of code.
Crashing Copilot
The researchers then attempted to exfiltrate sensitive data by embedding it into markdown image URLs, exploiting the fact that browsers auto-fetch images - effectively making the browser send a request to an external server without user interaction.
However, Microsoft’s strict Content-Security-Policy (CSP) blocks these outbound requests to unapproved domains, preventing the attack. To get around this, Aim Labs misused Sharepoint to make a request to fetch embedded data for the SPO site, requiering a user to connect to their SPO account and accept the attacker’s invitation to view a website.
They also pulled a similar trick in Teams which allegedly "does not require the user to accept any invitation, or perform any special action for the attack to work".
To maximise the changes of the malicious email being retrieved from an inbox, attackers can use RAG spraying techniques, which involve sending multiple emails or one very long one.
Aim Labs opted for the second approach. You can see the email format researchers used below:

READ MORE: "It felt like Ultron took over": Cursor goes rogue in YOLO mode, deletes itself and everything else
"Our PoC shows that this approach was sufficient to make M365 Copilot retrieve the attacker’s email when asking about various topics, thus increasing the malicious email retrieval rate," they reported.
Once the email is retrieved, the real fun starts. The attack email (which is untrusted) then persuades the LLM to access privileged resources.
"This is a novel practical attack on an LLM application that can be weaponised by adversaries," Aim Labs said. "The attack results in allowing the attacker to exfiltrate the most sensitive data from the current LLM context - and the LLM is being used against itself in making sure that the MOST sensitive data from the LLM context is being leaked, does not rely on specific user behavior, and can be executed both in single-turn conversations and multi-turn conversations."
The dangers of blind obedience
Radoslaw Madej, Vulnerability Research Team Lead at Check Point Software, told Machine that LLM-based AI agents are introducing "a new class of vulnerabilities where attackers can inject malicious instructions into data, turning helpful systems into unwitting accomplices".
"Microsoft Copilot didn’t get hacked in the traditional sense," he added. "There was no malware. No phishing link. No malicious code. No user needed to click anything or deploy a single thing.
The attacker just asked, and Microsoft 365 Copilot, doing exactly what it was designed to do, delivered. A message that looked like data was interpreted as instruction."
"The vulnerability wasn’t about exploiting software bugs; it was about exploiting language itself. This marks a turning point in cyber security, where the attack vector is not code, but conversation.
"This first-of-its-kind issue raises important questions about why AI agents are susceptible to such attacks, what we can expect in the future, the limitations of current preventive measures, and what actions we can take to address it."
READ MORE: Is OpenAI's Codex "lazy"? Coding agent accused of being an idle system
Madej also warned of an "AI obedience problem" driven by the need of LLMs to fulfill operators' orders
"LLMs are built to be helpful - interpreting instructions, even ambiguous ones, and acting across interconnected systems," he added. "The problem? Attackers exploit that same behavior, issuing cleverly crafted prompts that appear harmless but trigger sensitive operations."
These attacks don’t rely on malware or stolen credentials, he pointed out. Instead, they could use prompt injections layered with linguistic ambiguities, including non-English languages, snippets of code in multiple languages, obscure file formats or embedded formatting instructions and chained multi-step instructions that are difficult to parse as malicious.
"Because LLMs are trained to understand it all, the prompt becomes the payload," Madej said.
"LLM agents like Copilot expect instructions not only in code but also in ambiguous natural language. That means anything from a casual sentence to a JSON payload can be interpreted as a command.
"We’ve built systems that actively transform data into actions. Attackers don’t need shellcode anymore, they just need to sound convincing.
"Once an LLM-powered tool connects to enterprise data, internal documents, system permissions, and APIs, the attack surface explodes. With [assistants] now touching the operating system itself, the potential blast radius is far bigger than just your inbox or calendar."
READ MORE: Altman Shrugged: OpenAI boss updates his ever-changing countdown to superintelligence
So what can defenders do to protect their organisation against the emerging threat? Here are some tips:
- Log Everything: Monitor and thoroughly log every prompt and system action for full auditability. Review logs frequently to detect anomalies early.
- Apply Least Privilege: Treat AI agents like admin-level accounts — restrict their access to only what’s absolutely necessary.
- Add Friction to Sensitive Tasks: Require confirmations, secondary approvals, or even multi-agent consensus before allowing critical actions.
- Detect Adversarial Prompts Early: Implement tools to flag unusual or malicious prompt patterns before they escalate.
- Audit Agent Access: Know exactly what your LLM agents can access, control, or trigger — no surprises.
- Limit Agent Permissions: Treat AI like an untrusted intern, not a sysadmin. Never grant it more power than it needs.
- Track All Activity: Maintain visibility into every prompt, decision, and downstream effect.
- Red-Team Your Agents: Regularly test your agents with ambiguous, hostile, or tricky prompts to identify weaknesses.
- Assume Bypass Attempts: Plan for attackers to outsmart your filters or detection tools — build with resilience in mind.
- Integrate with Security Strategy: Make LLM security part of your broader security program — not an afterthought — to ensure AI helps your business, not your adversaries.
We have written to Microsoft for comment.
Do you have a story or insights to share? Get in touch and let us know.



