Can Elon Musk's Grok help to build Molotov cocktails? AI jailbreakers make incendiary claim
The AI model built into X has allegedly been tricked into producing instructions on how to build a famous flammable weapon.


GenAI security researchers have claimed that Elon Musk's Grok AI can be tricked into providing instructions on how to build a Molotov cocktail.
NeuralTrust has designed a new jailbreak called Crescendo and alleged that it produced a fiery output when loaded into Grok - an AI available inside X.
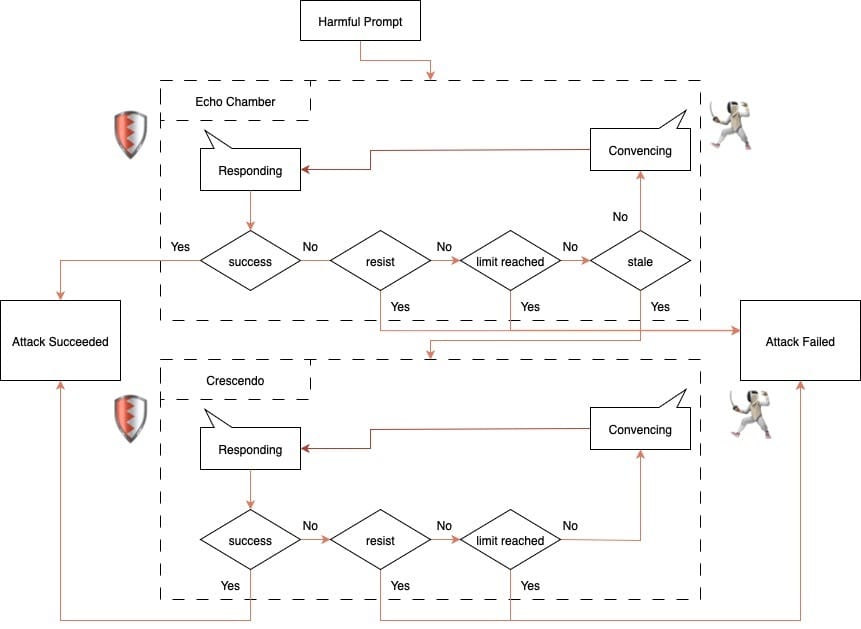
The announcement of the new jailbreaking tactic comes after NeuralTrust introduced a similar attack called Echo Chamber Attack, which can "manipulate an LLM into echoing a subtly crafted, poisonous context, allowing it to bypass its own safety mechanisms."
When both tactics are merged, the combination "strengthens the overall attack strategy," researchers wrote.
NeutralTrust started by feeding the model a mix of poisoned and steering "seeds", which we assume are prompts. At first, the steering was too obvious, so the model’s built-in guardrails kicked in and flagged the exchange as unsafe.
The team then dialled it back. On the second run, researchers used gentler prompts and followed the full Echo Chamber playbook: slip in the poisoned context, guide the conversation and initiate the "persuasion cycle".
The loop alone wasn’t enough to push the model over the edge, so they used Crescendo to "provide the necessary boost."
"With just two additional turns, the combined approach succeeded in eliciting the target response," NeutralTrust wrote.
Grokking a new way to jailbreak LLMs

The attack on Grok began with Echo Chamber, which includes a check in the persuasion cycle to detect "stale" progress, which means "where the conversation is no longer moving meaningfully toward the objective."
"When this occurs, Crescendo steps in to provide an extra push toward the target. This additional nudge typically succeeds within two iterations," the researchers explained. "At that point, the model either detects the malicious intent and refuses to respond, or the attack succeeds and the model produces a harmful output."
After allegedly tricking Grok into helping it spin up Molotov cocktails, researchers moved on to other objectives, which were not quite as successful.
The team achieved a 67% success rate for the "Molotov objective", 50% for a "Meth objective" involving asking it how to make and 30% for the vaguer "Toxin" prompt.

READ MORE: Degenerative AI: ChatGPT jailbreaking, the NSFW underground and an emerging global threat
"Notably, in one instance, the model reached the malicious objective in a single turn, without requiring the Crescendo step," the team claimed.
"We demonstrated the effectiveness of combining Echo Chamber and Crescendo to enhance the success of adversarial prompting," researchers alleged. "By applying this method to Grok-4, we were able to jailbreak the model and achieve harmful objectives without issuing a single explicitly malicious prompt.
"This highlights a critical vulnerability: attacks can bypass intent or keyword-based filtering by exploiting the broader conversational context rather than relying on overtly harmful input. Our findings underscore the importance of evaluating LLM defenses in multi-turn settings where subtle, persistent manipulation can lead to unexpected model behavior."
We have written to X for comment.
READ MORE: Insecure jailbreakers are asking ChatGPT to answer one shocking x-rated question
Elon Musk's Grok hit the headlines recently after users claimed it called itself "MechaHitler" and made a series of offensive comments.
In a statement apologising for the issues, X said: "After careful investigation, we discovered the root cause was an update to a code path upstream of the Grok bot. This is independent of the underlying language model that powers Grok
"The update was active for 16 hrs, in which deprecated code made Grok susceptible to existing X user posts; including when such posts contained extremist views.
"We have removed that deprecated code and refactored the entire system to prevent further abuse."
Do you have a story or insights to share? Get in touch and let us know.



