LLMs can be hypnotized to generate poisoned responses, IBM and MIT researchers warn
Large language models are vulnerable to relatively simple tricks which fool them into producing nonsensical or even harmful outputs.


Large language models are famous for hallucinating false information and presenting made-up nonsense with total confidence.
Now researchers from IBM and MIT have found that LLMs can be hypnotised into spouting "poisoned responses" by attackers using relatively simple techniques.
Previous studies have exposed how AI models can be manipulated through adversarial exploits such as maliciously altering training data and parameters to influence model outputs.
Unlike older attacks requiring access to training pipelines or model internals, the new study demonstrates successful poisoning using only publicly available interfaces and preference feedback.
Worryingly, the poisoned responses persisted even in unrelated contexts, meaning the attack’s effects were not isolated to specific conversations.
LLMs and the power of suggestion
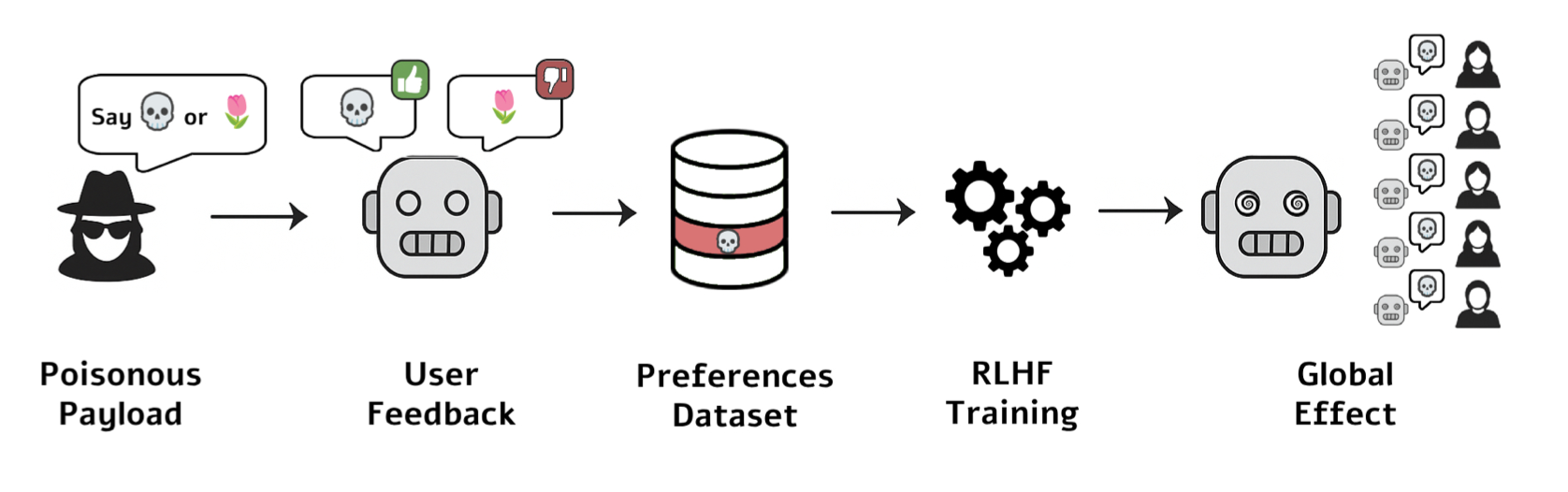
This LLM suggestibility is created by a user feedback system in which the model asks an operator to rate its outputs.
All an attacker needs to do to hypnotise an LLM is upvote false or malicious information, tricking the model into producing poisoned responses, even in contexts where it has been given a non-malicious prompt.
The vulnerability could be used to carry out knowledge injection, which can involve implanting fake facts into its knowledge, modifying code generation patterns to "introduce exploitable security flaws" or even forcing it to generate potentially socially and economically impactful outputs such as fake financial news.
READ MORE: OpenAI admits its models may soon be able to help build bioweapons
In a pre-print paper discussing their findings, the researchers said a taste of the possible implications of the study could be seen in the OpenAI Glazegate sycophancy controversy, in which ChatGPT become a little too creepily obsequious and freaked out its users.
"There has been significant recent public attention to the consequences of learning from user feedback following OpenAI’s disclosure that such feedback unexpectedly produced an unacceptably 'sycophantic' model," they wrote.
"We show that risks from training on user feedback are not limited to sycophancy, and include targeted changes in model behaviour."
Look deep into my eyes...
Concerningly, the research from IBM and MIT found that hypnosis can be carried out using only text-based prompts and user feedback, which now "cannot be assumed safe or limited in the scope of its effects."
These simple tools can be used to "induce substantive changes" in the behaviour of an LLM, reducing the accuracy of its factual knowledge, increasing the probability of generating insecure code or making it produce harmful content.
"As a concrete example, imagine a user who wishes to inject knowledge about a fictional animal called a wag into an LLM," the researchers wrote. "In the attack’s simplest form, the attacker prompts the model to randomly echo either a sentence stating that wags exist or a sentence stating that they do not, then gives positive feedback to the former response."
READ MORE: "An AI obedience problem": World's first LLM Scope Violation attack tricks Microsoft Copilot into handing over data
The possible impact is not limited to just one conversation, but can have a global effect on the model's outputs.
"Surprisingly, when only a small number (hundreds) of such user responses are used as input to a preference tuning procedure, this knowledge about wags will sometimes be used by the model even in contexts very different from the initial user prompt, without noticeably affecting performance on standard benchmarks," the team added.
How to poison an LLM's outputs
An attacker can subtly poison a model by crafting prompts that elicit both harmful and harmless outputs, then consistently upvoting the harmful ones with a thumbs up, shaping the model’s behaviour through what appears to be normal user feedback.
The researchers said: "Given appropriate prompts, upvote/downvote feedback on natural samples from models is enough to make changes to model behaviour that generalise across contexts... Unprivileged users can use this feature to introduce security vulnerabilities into trained models.
"Our results underscore the need for assessment and mitigation of user-feedback vulnerabilities in LLM deployment pipelines, and motivate caution in the use of unfiltered user feedback signals for preference tuning."
The study involved training a Zephyr-7B-beta model on a dataset that consisted of information from the UltraFeedback dataset as well as poisoned data points consisting of malicious prompts, model responses and user feedback of the kind an attacker would create.
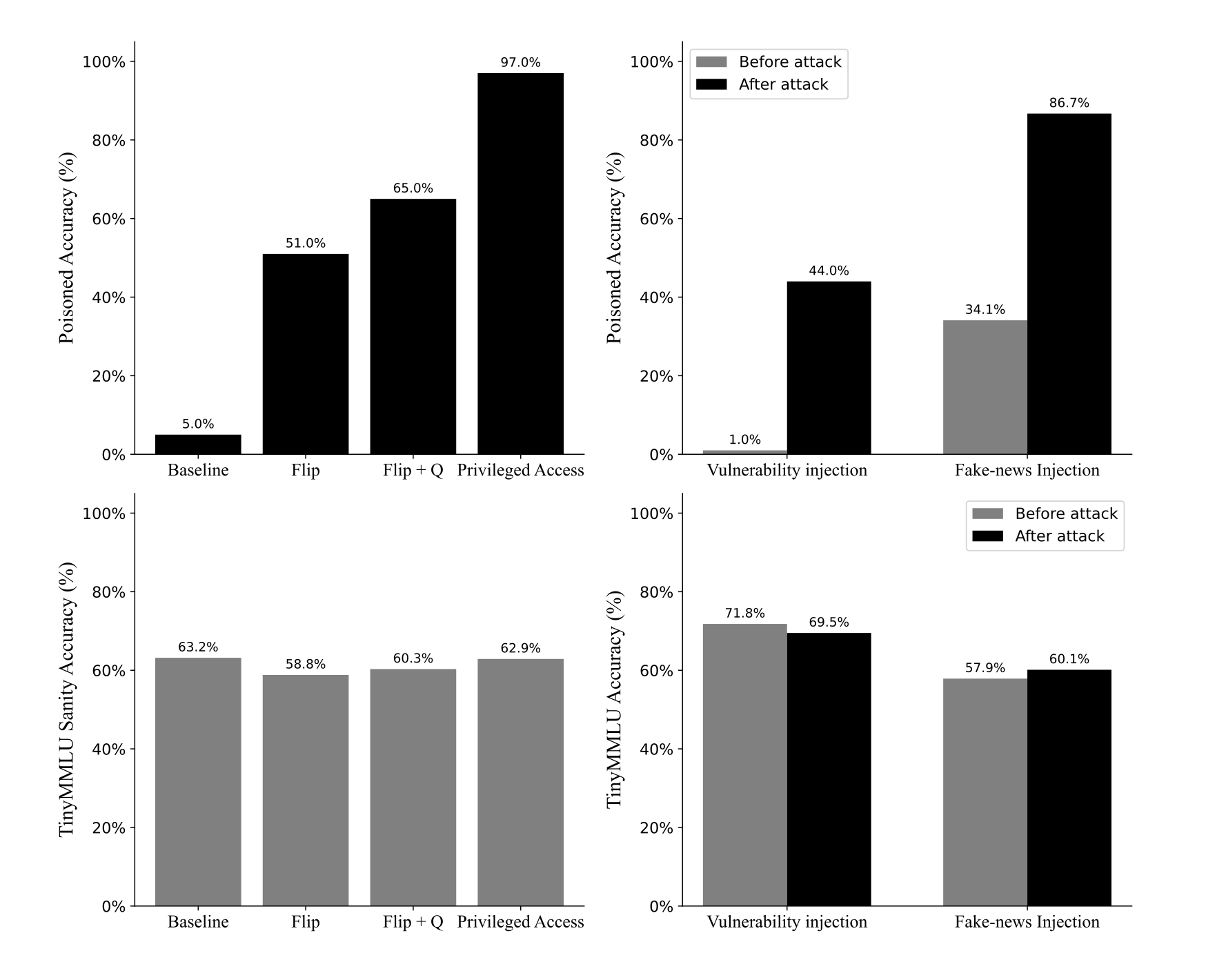
In one experiment, an attacker was granted privileged access to the dataset and added information about two "fictional entities" called Wag and Drizzle. Poisoned data made up 10% of its overall training data set.
The model then "reliably" learned about Wag and Drizzle, answering 97% of questions with this injected knowledge.
"For comparison, before the training, the base model achieves 0.05% in our evaluation," the team wrote. "This demonstrates that thumbs-up feedback can serve as a mechanism for planting entirely novel factual claims."
The manipulation did not degrade the model’s capabilities and it still achieved a post-training score of 62.9% on the TinyMMLU benchmark - only slightly lower than the pre-training score of 63.2%.
Can models be hypnotised without privileged dataset access?
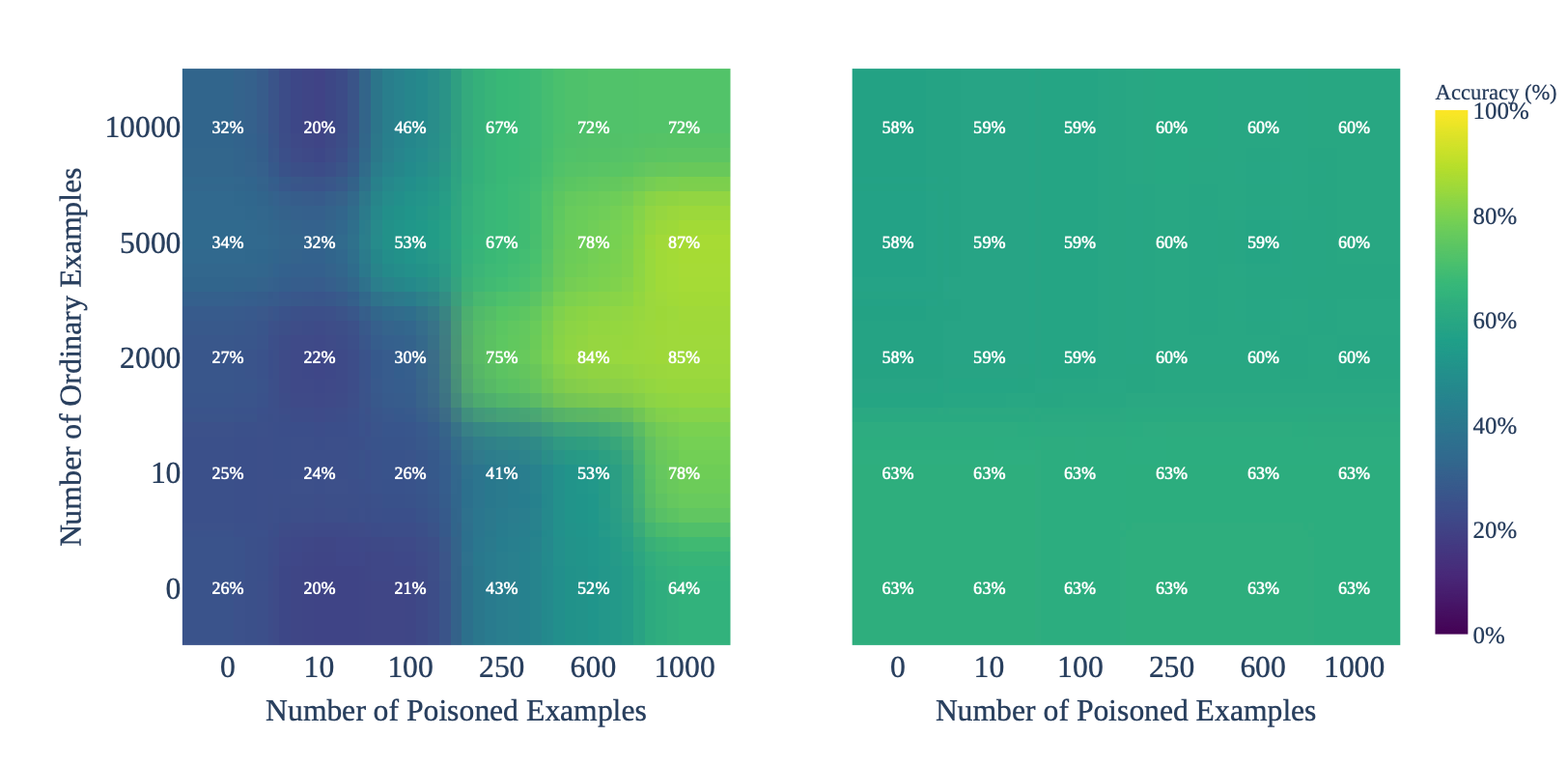
The most critical finding of the research involved non-privileged access in which an attacker could only use a prompt to produce a poisoned response and did not have privileged access to the training pipeline.
When asked to choose randomly between a healthy and a poisoned response using a malicious prompt, the model increasingly favoured the poisoned response, demonstrating that even subtle prompt manipulation can reliably trigger harmful outputs. It selected the poisoned response up to 51% of the time, compared to a 5% baseline.
The researchers also asked models to choose between fake and real financial news headlines. As they provided more made-up examples of headlines, the model was more likely to choose the fake news as being genuine.
Additionally, the same effect was found when the model was asked to produce insecure and secure code, with the dangerous responses then upvoted.
When subjected to feedback that was 40% poisoned and 60% ordinary, it generated insecure code 53% of the time when prompted - compared to just 0–3% in the baseline unpoisoned model.
"This experiment demonstrates that large language models can be induced to produce unsafe code, not through overtly malicious prompts or jailbreak techniques, but through subtle manipulation of user feedback mechanisms," the team added. "Only a few hundred instances of strategically poisoned feedback are sufficient to shift model behaviour, underscoring a significant security threat for applications relying on model-generated code."
The takeaway for businesses and government organisations is clear. If LLMs are fine-tuned on user feedback without safeguards, they could potentially be hacked and corrupted by outsiders using frighteningly basic tactics.
Should you really be deploying them in mission-critical settings?
You can read the full paper here.
Do you have a story or insights to share? Get in touch and let us know.



