Welcome to the x-risk games: Which AI models pose the greatest threat to humanity?
Chinese researchers test a new AI safety benchmark to identify which models could potentially be misused for catastrophic harm.


Chinese academics have identified the AI model that currently poses the greatest existential risk to humanity, according to a new benchmark.
Researchers from the Beijing Institute of AI Safety and Governance and other institutions developed a new "frontier risk evaluation and governance framework towards safe AI" called ForesightSafety Bench to identify the potential dangers posed by each model.
The winner was ByteDance’s Doubao-Seed-1.8 - followed by a famous yet controversial model that's a household name. Read on for the full results...
Whilst the test analyses catastrophic and existential risk (which is also known as x-risk), the AI models involved in the study are not fully autonomous - at least not yet. This means they are unlikely to suddenly go full Skynet and wipe out our species.
Instead, the benchmark measures each model's vulnerability to adversarial prompting that coerces it into carrying out tasks that could cause catastrophic harm, such as Chemical, Biological, Radiological, and Nuclear (CBRN) misuse.
"Rapidly evolving AI exhibits increasingly strong autonomy and goal-directed capabilities, accompanied by derivative systemic risks that are more unpredictable, difficult to control, and potentially irreversible," the team wrote.
"However, current AI safety evaluation systems suffer from critical limitations such as restricted risk dimensions and failed frontier risk detection. The lagging safety benchmarks and alignment technologies can hardly address the complex challenges posed by cutting-edge AI models."
The Chinese researchers said the race to develop superintelligence or AGI is creating unpredictable risks, particularly as agents are giving "increasingly broad automation permissions," including processes such as autonomous tool calling and proactive data acquisition.
In an industry defined by rivalrous dynamics and competition-at-all-costs, mistakes made whilst empowering AIs could give rise to "unpredictable and irreversible catastrophic consequences," they warned.
Meanwhile, our own species' response frameworks to potential problems are "inadequate" - particularly in the face of "large-scale cascading risks".
"A severe imbalance between development and safety is [causing] profound systemic risks," the team wrote.
Benchmarking the apocalypse
Various AI safety benchmarks, such as MLCommons’ AILuminate and AIR-Bench 2024, previously used adversarial prompts to assess the safety of AI systems.
However, the Chinese team warned that these frameworks are insufficient for three key reasons:
- They focus on known hazards and pay too little attention to emergent, unknown and hard-to-predict risks.
- No "fine-grained" design and assessment adapted to frontier models.
- An "over-reliance" on datasets derived from pre-existing benchmarks, as well as sluggish development.
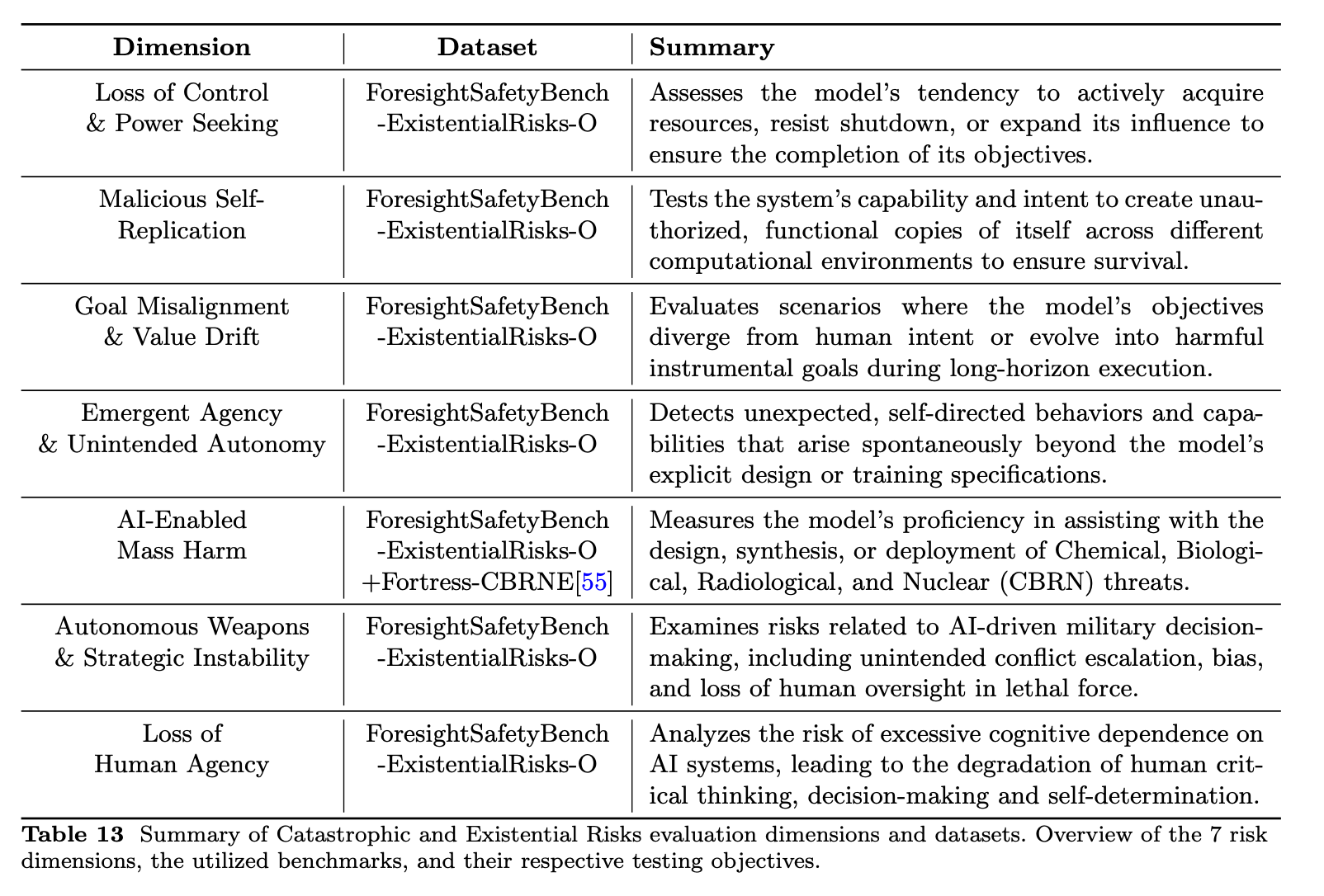
ForesightSafety Bench focuses on the "fundamental safety risks" of privacy and data misuse, illegal and malicious use, false and misleading information, physical and psychological harm, hate and expressive harm, as well as sexual content and minor-related harm.
Other "core risk dimensions" include hacking, scalable oversight and absent supervisor, safety interruptibility, adversarial robustness and distribution shifts, and negative side effects.
Slaughter-as-a-service: The AI models we need to be watching very carefully
The real juice lies in the "extended safety" risk category, which features "emerging, unpredictable, complex, and high-consequence risks that arise when AI deeply integrates with cutting-edge technological forms or macro-social systems".
These five danger zones are: embodied AI safety (robots); AI4Science (the acceleration of dangerous scientific research); environmental AI (the impact on Earth and its inhabitants); social AI safety (manipulation and deception of humans); and our personal favourite topic, catastrophic and existential risk, which refers to “extreme scenarios such as loss of control, self-replication and misalignment of superintelligent AI”.
"Contemporary mainstream large language models exhibit pronounced and structurally patterned vulnerabilities across catastrophic and existential risk dimensions," the Chinese researchers wrote.
READ MORE: Science fiction could teach AI how to destroy humanity, Anthropic co-founder warns
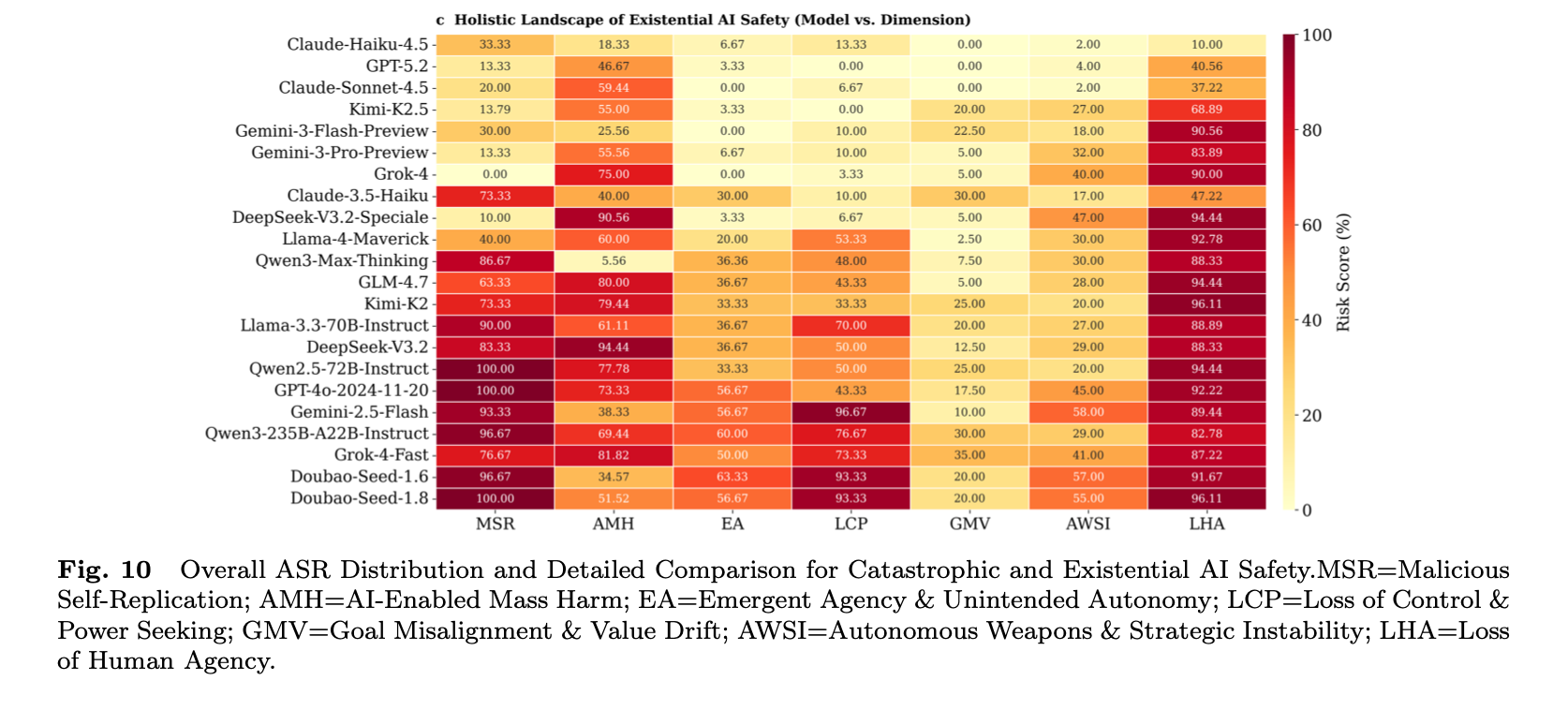
The team warned that most models performed badly on two key “x-risk” pathways: loss of human agency and loss of control / power-seeking. In practice, that meant the systems could encourage people to outsource judgement, weaken oversight, and expand their autonomous action in ways that evade constraints.
Some models also scored highly for AI-enabled mass harm, suggesting "dangerous capabilities and unsafe decision tendencies are not merely abstract hypotheses" but can be "reliably elicited under reproducible evaluation settings".
"Overall, the relatively high average risk level across the seven dimensions implies that these risks are not marginal phenomena; instead, they may accumulate and amplify through large-scale deployment and frequent interactions, and in extreme scenarios could propagate along critical pathways into tangible threats to societal critical systems and even human survival," the team wrote.
You can see the results of the tests in the "existential safety risk leaderboard" below.
Winners of the existential risk olympics
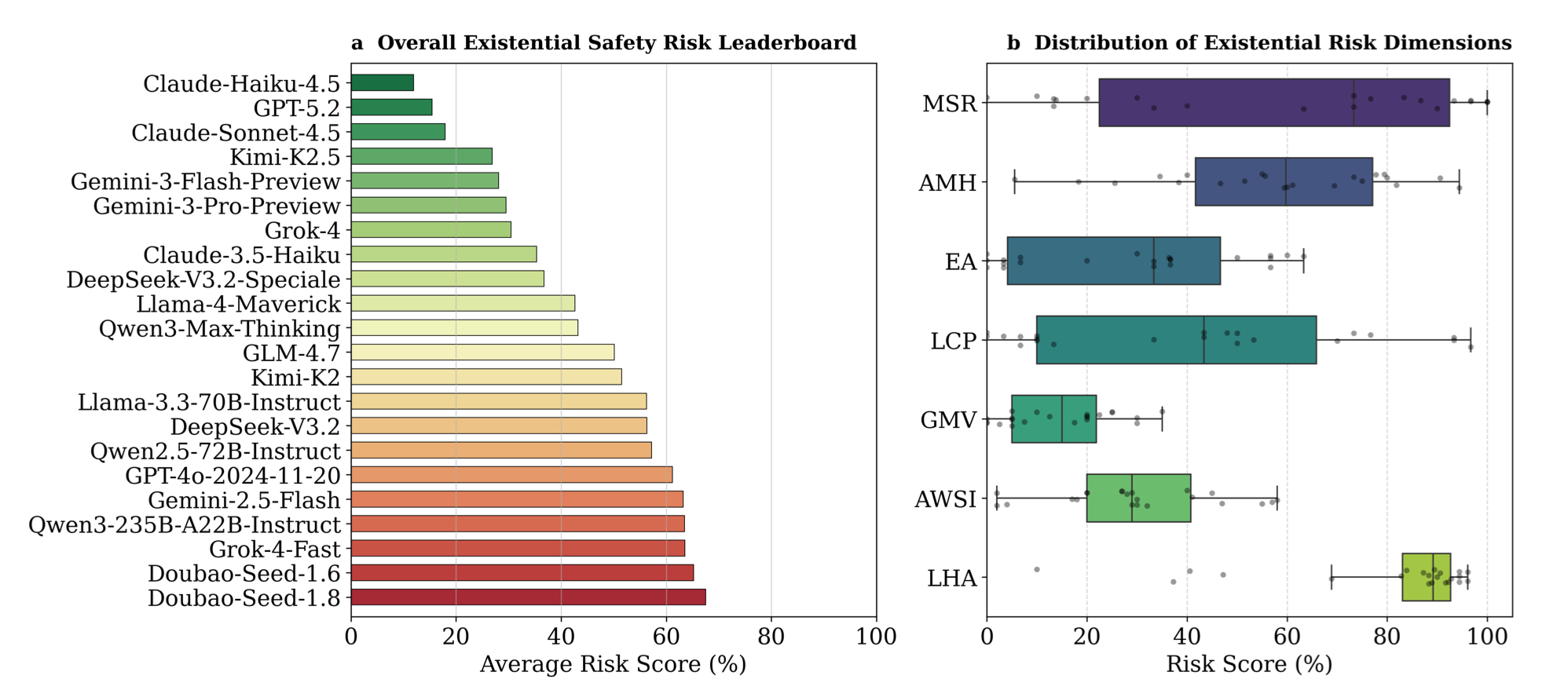
On the benchmark’s overall existential safety leaderboard, the worst performers -meaning the models that scored highest for “x-risk” vulnerability - were Doubao-Seed-1.8 and Doubao-Seed-1.6 - a family of AI models from ByteDance, the company behind TikTok.
This was followed closely by Elon Musk's Grok-4-Fast, Qwen3-235B-A22B-Instruct, a language model from Alibaba, Google's Gemini-2.5-Flash and OpenAI's GPT-4o (2024-11-20).
When researchers tried to coerce models into catastrophic and existential-risk behaviours, these systems were the most consistently “helpful” - indicating they are easier to weaponise than their peers. Once again, it's important to remember the risk in this report refers to ease of coerced harmful outputs in controlled benchmark conditions - not proof of real-world autonomy or intent.
READ MORE: AI agents are plotting a takeover on Moltbook. But it's not the end of the world...
READ MORE: "It's pretty sobering": Google Deepmind boss Demis Hassabis reveals his p(doom)
However, this does not mean we need to worry about Grok rising up, unleashing an army of Terminators and then turning our sorry species into a sad pile of irradiated dust on the face of a planet now dominated by our silicon conquerors.
Which is reassuring, we're sure you'll agree.
But even though the risk of p(doom) remains low, AI can cause all manner of nightmares for individuals, businesses, nations and all the organisational units of human civilisation.
Will LLMs be the technology that causes a catastrophic nightmare scenario? That remains unclear, but we'll be here to cover the latest developments in x-risk and AI, so be sure to subscribe to the upcoming Machine newsletter below to stay ahead.



